STAT 39000: Project 9 — Fall 2021
Motivation: One of the primary ways to get and interact with data today is via APIs. APIs provide a way to access data and functionality from other applications. There are 3 very popular types of APIs that you will likely encounter in your work: RESTful APIs, GraphQL APIs, and gRPC APIs. We will address some pros and cons of each, with a focus on the most ubiquitous, RESTful APIs.
Context: This is the second in a series of 4 projects focused around APIs. We will learn some basics about interacting and using APIs, and even build our own API.
Scope: Python, APIs, requests, fastapi
Dataset(s)
The following questions will use the following dataset(s):
-
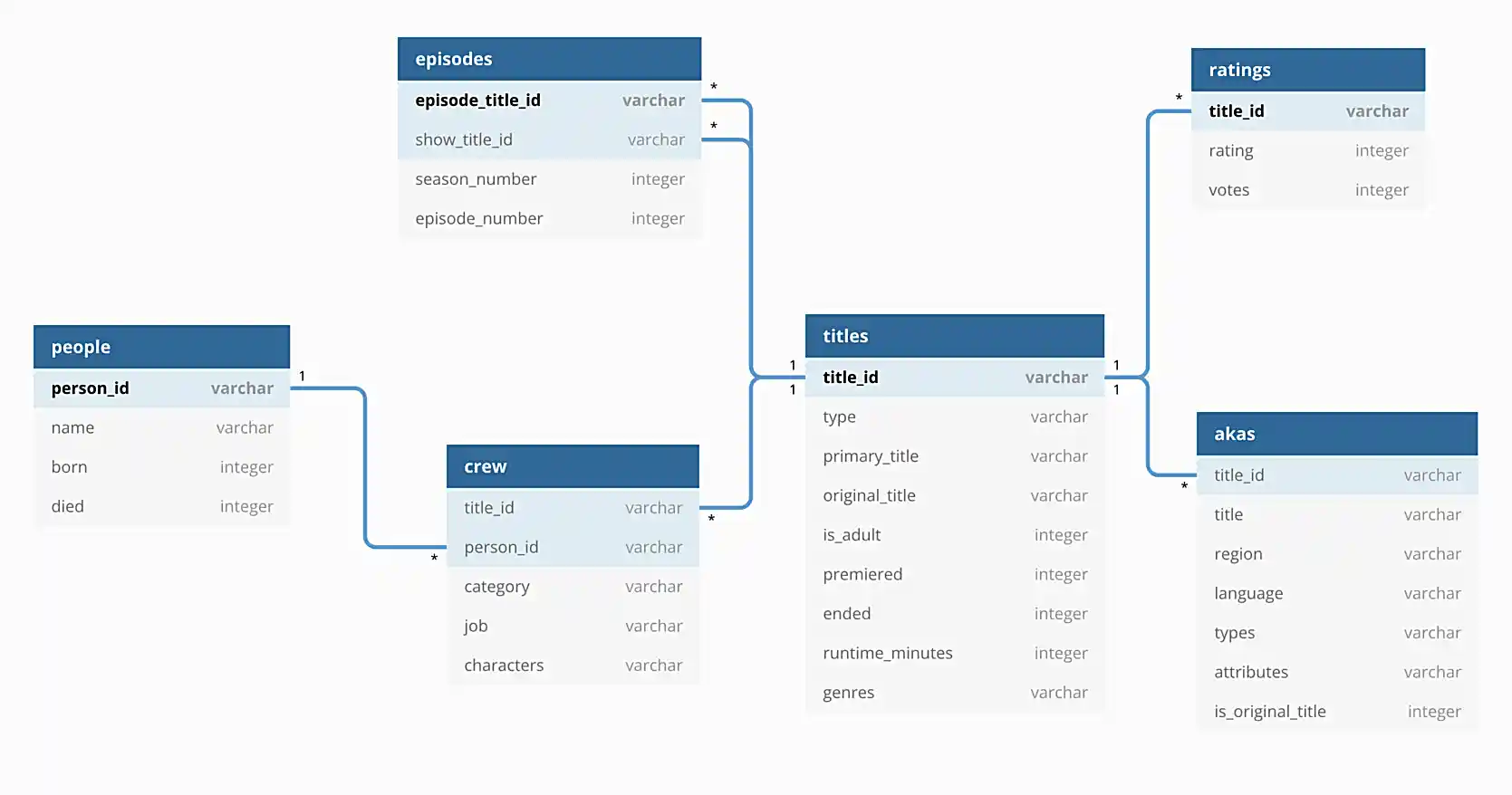
/depot/datamine/data/movies_and_tv/imdb.db
In addition, the following is an illustration of the database to help you understand the data.
Questions
Question 1
Begin this project by cloning our repo and installing the required packages. To do so, run the following in a bash cell.
%%bash
cd $HOME
git clone git@github.com:TheDataMine/f2021-stat39000-project9.gitThen, to install the required packages, run the following in a bash cell.
%%bash
module unload python/f2021-s2022-py3.9.6
cd $HOME/f2021-stat39000-project9
poetry installNext, let’s identify a port that we can run our API on. In a bash cell, run the following.
%%bash
portYou will get a port number, like the following, for example.
1728
From this point on, when we mention the port 1728, please replace it with the port number you were assigned. Open a new terminal tab so that we can run our API, alongside our notebook.
Next, you’ll need to add a .env file to your f2021-stat39000-project9 directory, with the following content. (Pretty much just like the previous project!)
DATABASE_PATH=/depot/datamine/data/movies_and_tv/imdb.db
In your terminal (not a bash cell), run the following.
module use /scratch/brown/kamstut/tdm/opt/modulefiles
module load poetry/1.1.10
cd $HOME/f2021-stat39000-project9
poetry run uvicorn app.main:app --reload --port 1728Upon success, you should see some output similar to:
INFO: Will watch for changes in these directories: ['$HOME/f2021-stat39000-project9'] INFO: Uvicorn running on http://127.0.0.1:1728 (Press CTRL+C to quit) INFO: Started reloader process [25005] using watchgod INFO: Started server process [25008] INFO: Waiting for application startup. INFO: Application startup complete.
Fantastic! Leave that running in your terminal, and test it out with the following request in a regular Python cell in your notebook.
|
Make sure to replace 1728 with the port number you were assigned. |
import requests
resp = requests.get("http://localhost:1728")
print(resp.json())You should receive a Hello World message, great!
|
Throughout this project, be patient waiting for your requests to complete — sometimes they take a while. If it is taking too long, you can always try killing the server. To do so, open the terminal tab and hold ctrl and press c. This will kill the server. Once killed, just restart it using the same command you used previously to start it. Finally, there are now 2 places to check for errors and print statements: the terminal and the notebook. When you get an error be sure to check both for useful clues! Keep in mind that you only need to modify 3 files: |
|
Please test the requests in your notebook with the code we provide you. We’ve tested them and know that they work. If you choose to test them with a different movie/tv show/etc., you could get unexpected errors related to our |
-
Code used to solve this problem.
-
Output from running the code.
Question 2
Okay, so the goal of the next 4 or so questions is to put together the following API endpoints, that return simple JSON responses, with the desired data. You can almost think of this as one big fancy interface to return data from our database in JSON format — that is pretty much what it is! BUT we have the capability to do nice data-processing on the data before it is returned, which can be difficult using just SQL.
The following are a list of endpoints that we already have implemented for you, to help get you started.
|
Here the To be very clear, the following would be an example making a request to the |
The following are a list of endpoints we want you to build!
The following are a list of endpoints that we will provide you in project 10.
This will be a very guided project, so please be sure to read the instructions carefully, and as you are working, use your imagination to imagine what other cool potential and possibilities building APIs can have! We are only scratching the surface here!
Okay, let’s get started with the first endpoint.
Implement this endpoint. What files do you need to modify?
-
Add the following function to
main.py@app.get( "/cast/{title_id}", response_model=list[CrewMember], summary="Get the crew for a title_id.", response_description="A crew." ) async def get_cast(title_id: str): cast = get_cast_for_title(title_id) return cast -
Add the following query to
queries.sql, filling in the query-- name: get_cast_for_title -- Get the cast for a given title SELECT statement here
Make sure you don’t add the carrot "^" to the end of this particular query. Otherwise, it will only return 1 result.
In your
queries.sqlfile, anything starting with a colon is a placeholder for a variable you will pass along. Check out theimdb.pyfile and thequeries.sqlfile to better understand. -
In your
imdb.pymondule, fill out the skeleton function calledget_cast_for_title, that returns a list ofCrewMemberobjects.Here is the function you can finish writing:
def get_cast_for_title(title_id: str) -> list[CrewMember]: # Get the cast for the movie, and close the database connection conn = sqlite3.connect(database_path) results = queries.get_cast_for_title(conn, title_id = title_id) conn.close() # Create a list of dictionaries, where each dictionary is a cast member # INITIALIZE EMPTY LIST for member in results: crewmemberobject = CrewMember(**{key: member[i] for i, key in enumerate(CrewMember.__fields__.keys())}) # APPEND crewmemberobject TO LIST return castCheck out the
get_movie_with_idfunction for help! It should just be a few small modifications.
To test your endpoint, run the following in a Python cell in your notebook.
import requests
resp = requests.get("http://localhost:1728/cast/tt0076759")
print(resp.json())[{'title_id': 'tt0076759', 'person_id': 'nm0000027', 'category': 'actor', 'job': None, 'characters': '["Ben Obi-Wan Kenobi"]'}, {'title_id': 'tt0076759', 'person_id': 'nm0000148', 'category': 'actor', 'job': None, 'characters': '["Han Solo"]'}, {'title_id': 'tt0076759', 'person_id': 'nm0000184', 'category': 'director', 'job': None, 'characters': '\\N'}, {'title_id': 'tt0076759', 'person_id': 'nm0000402', 'category': 'actress', 'job': None, 'characters': '["Princess Leia Organa"]'}, {'title_id': 'tt0076759', 'person_id': 'nm0000434', 'category': 'actor', 'job': None, 'characters': '["Luke Skywalker"]'}, {'title_id': 'tt0076759', 'person_id': 'nm0002354', 'category': 'composer', 'job': None, 'characters': '\\N'}, {'title_id': 'tt0076759', 'person_id': 'nm0156816', 'category': 'editor', 'job': 'film editor', 'characters': '\\N'}, {'title_id': 'tt0076759', 'person_id': 'nm0476030', 'category': 'producer', 'job': 'producer', 'characters': '\\N'}, {'title_id': 'tt0076759', 'person_id': 'nm0564768', 'category': 'producer', 'job': 'producer', 'characters': '\\N'}, {'title_id': 'tt0076759', 'person_id': 'nm0852405', 'category': 'cinematographer', 'job': 'director of photography', 'characters': '\\N'}]
-
Code used to solve this problem.
-
Output from running the code.
Question 3
Implement the following endpoint.
For this question, we will leave it up to you to figure out what files to modify in what ways.
|
Check out the functions that are already implemented for help — it will be very similar! If you get an error at any step of the way, read the errors — they tell you what is missing 90% of the time — or at least hint at it! We’ve provided you with skeleton functions (with comments) in |
|
One of the cool things that make APIs so useful is how easy it is to share data in a structured way with others! While there is typically a bit more setup to expose the API to the public — it is really easy to share with other people on the same system. If you and your friend were on the same node, for example, |
To test your endpoint, run the following in a Python cell in your notebook.
import requests
resp = requests.get("http://localhost:1728/tv/tt5180504")
print(resp.json())Which, should return the following:
{'title_id': 'tt5180504', 'type': 'tvSeries', 'primary_title': 'The Witcher', 'original_title': 'The Witcher', 'is_adult': False, 'premiered': 2019, 'ended': None, 'runtime_minutes': 60, 'genres': [{'genre': 'Action'}, {'genre': 'Adventure'}, {'genre': 'Fantasy'}]}
And also test with the following:
import requests
resp = requests.get("http://localhost:1728/tv/tt2953050")
print(resp.json())Which, should return the following:
{'detail': "Title with title_id 'tt2953050' is not a tv series, it is a movie."}
Similarly:
import requests
response = requests.get("http://localhost:1728/tv/tt8343770")
print(response.json())Which, should return the following:
{'detail': "Title with title_id 'tt8343770' is not a tv series, it is a tvEpisode."}
-
Code used to solve this problem.
-
Output from running the code.
Question 4
Implement the following endpoint.
Okay, don’t be overwhelmed! There are only 3 files to modify and add code to: main.py, queries.sql, and imdb.py. Aside from that, you are just making requests library calls to test out the API (from within your notebook).
|
We’ve provided you with the following queries (in -- name: get_title_type$ -- Get the type of title, movie, tvSeries, etc. -- name: get_seasons_in_show$ -- Get the number of seasons in a show -- name: get_episodes_in_season$ -- Get the number of episodes in a season for a given title with given title_id -- name: get_episode_for_title_season_number_episode_number^ -- Get the episode title info for the title_id, season number and episode number |
-
Use the
get_title_typequery to check if the type is nottvSeries. -
Use the
get_seasons_in_showquery to check if the providedseason_numberis valid. For example it must be a positive number and less than or equal to the number of seasons actually in the given show. -
Use the
get_episodes_in_seasonquery to check if the providedepisode_numberis valid. For example it must be a positive number and less than or equal to the number of episodes actually in the given season.
All of these queries should be called in your get_show_for_title_season_and_episode function in imdb.py. We’ve provided you with skeleton code with comments to help — just fill it in!
Finally, you should make a get_episode function in main.py, with the following signature:
async def get_episode(title_id: str, season_number: int, episode_number: int):To test your endpoint, run the following in cells in your notebook.
import requests
response = requests.get("http://localhost:1728/tv/tt1475582/seasons/1/episodes/2")
print(response.json()){'title_id': 'tt1664529', 'type': 'tvEpisode', 'primary_title': 'The Blind Banker', 'original_title': 'The Blind Banker', 'is_adult': False, 'premiered': 2010, 'ended': None, 'runtime_minutes': 89, 'genres': [{'genre': 'Crime'}, {'genre': 'Drama'}, {'genre': 'Mystery'}]}
Also:
import requests
response = requests.get("http://localhost:1728/tv/tt1664529/seasons/1/episodes/2")
print(response.json()){'detail': "Title with title_id 'tt1664529' is not a tv series, it is a tvEpisode."}
Also:
import requests
response = requests.get("http://localhost:1728/tv/tt1475582/seasons/1/episodes/7")
print(response.json())And because there is no episode 7:
{'detail': 'Season 1 only 4 episodes and you requested episode 7.'}
Also:
import requests
response = requests.get("http://localhost:1728/tv/tt1475582/seasons/5/episodes/7")
print(response.json())And because there is no season 5:
{'detail': 'There are only 4 seasons for this show, you requested information about season 5.'}
|
Note that this error takes precedence over the fact that there are only 4 episodes and we requested info for episode 7. |
|
For this project you should submit the following files:
|
-
Code used to solve this problem.
-
Output from running the code.
Question 5 (Optional, 0 pts)
Implement the following endpoint.
To test your endpoint, run the following in a Python cell in your notebook.
import requests
response = requests.get("http://localhost:1728/tv/tt1475582/seasons/1/episodes")
print(response.json())[{'title_id': 'tt1664529', 'type': 'tvEpisode', 'primary_title': 'The Blind Banker', 'original_title': 'The Blind Banker', 'is_adult': False, 'premiered': 2010, 'ended': None, 'runtime_minutes': 89, 'genres': [{'genre': 'Crime'}, {'genre': 'Drama'}, {'genre': 'Mystery'}]}, {'title_id': 'tt1664530', 'type': 'tvEpisode', 'primary_title': 'The Great Game', 'original_title': 'The Great Game', 'is_adult': False, 'premiered': 2010, 'ended': None, 'runtime_minutes': 89, 'genres': [{'genre': 'Crime'}, {'genre': 'Drama'}, {'genre': 'Mystery'}]}, {'title_id': 'tt1665071', 'type': 'tvEpisode', 'primary_title': 'A Study in Pink', 'original_title': 'A Study in Pink', 'is_adult': False, 'premiered': 2010, 'ended': None, 'runtime_minutes': 88, 'genres': [{'genre': 'Crime'}, {'genre': 'Drama'}, {'genre': 'Mystery'}]}, {'title_id': 'tt1815240', 'type': 'tvEpisode', 'primary_title': 'Unaired Pilot', 'original_title': 'Unaired Pilot', 'is_adult': False, 'premiered': 2010, 'ended': None, 'runtime_minutes': 55, 'genres': [{'genre': 'Crime'}, {'genre': 'Drama'}, {'genre': 'Mystery'}]}]
And of course, continue to have the regular errors we’ve had so far:
import requests
response = requests.get("http://localhost:1728/tv/tt1475582/seasons/5/episodes")
print(response.json()){'detail': 'There are only 4 seasons for this show, you requested information about season 5.'}
And
import requests
response = requests.get("http://localhost:1728/tv/tt1664529/seasons/5/episodes")
print(response.json()){'detail': "Title with title_id 'tt1664529' is not a tv series, it is a tvEpisode."}
-
Code used to solve this problem.
-
Output from running the code.
|
Please make sure to double check that your submission is complete, and contains all of your code and output before submitting. If you are on a spotty internet connection, it is recommended to download your submission after submitting it to make sure what you think you submitted, was what you actually submitted. |